
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- System
- CodeEngn
- 유석종교수님
- c
- basicrce3
- Dreamhack
- Upstage
- backjoon
- 백준
- python
- pwnable
- bWAPP
- mount
- Linux
- AWS
- 자료구조
- fork-bomb
- EC2
- acc
- beebox
- wireshark
- cloud
- Reversing
- datastructure
- S3
- SISS
- 와이어샤크
- htmlinjection
- Reflected
- Systemhacking
- Today
- Total
Ctrl + Shift + ESC
CHAPTER 08 정렬 본문
8.1 정렬의 종류
정렬(sort) : 주어진 원소(레코드)들을 원하는 기준에 의해 나열하는 작업
ex) 파일을 크기 순서대로 정렬, 시험 점수를 내림차순으로 정렬
주 메모리에서 처리하는 내부 정렬(internal sort)과 하드 디스크와 같은 외부 기억장치에서 처리하는 외부 정렬(external sort)로 구분한다.

레코드는 정렬의 기준이 되는 key field와 다른 속성들로 이루어져 있다.
외부 정렬
정렬할 원소 개수가 메모리보다 훨씬 큰 경우 외부 정렬을 수행해야 한다.
외부 기억장치에 정렬해야 할 전체 원소의 수가 N개가 저장되어 있고, 메모리의 크기가 m이라고 가정하자.
외부 정렬은 다음과 같은 순서로 진행된다.
1. N개의 원소를 m으로 나누어 N / m 개의 세그먼트로 분할한다.
2. 각 세그먼트를 주메모리에 로드하여 내부 정렬 알고리즘으로 정렬한 후 다시 원래의 하드디스크 위치에 저장한다.
3. 정렬된 2개의 세그먼트 쌍에 대해서 합병 정렬을 수행한다.
4. 하나의 정렬된 세그먼트가 생성된 때까지 3번 과정을 반복한다.
정렬 알고리즘의 성능은 키 값의 비교 횟수와 데이터 이동 횟수 등에 의하여 평가된다.
다음은 대표적인 내부 정렬 알고리즘의 종류이다.
- 시간 복잡도가 O(n^2)인 알고리즘
- 선택 정렬(selection sort)
- 버블 정렬(bubble sort)
- 삽입 정렬(insertion sort)
- 쉘 정렬(quick sort)
- 보다 복잡한 알고리즘(시간 복잡도 O(nlogn))
- 퀵 정렬(quick sort)
- 힙 정렬(heap sort) - 7장에서 다룸
- 합병 정렬(merge sort)
- 기수 정렬(radix sort)
8.2. 선택 정렬
선택 정렬(selection sort) : 정렬할 원소 집합에서 최솟값(또는 최댓값)을 탐색하여 정렬 리스트로 이동시키고 정렬 대상에서 제외한다.
남은 원소들에 대해 이 과정을 반복하여 순서대로 최솟값(또는 최댓값)을 탐색하여 정렬을 수행한다.
선택 정렬에는 최솟값 우선 탐색 방법과 최댓값 우선 탐색 방법이 있다.
선택 정렬은 최솟값(또는 최댓값)을 찾는데 n번 비교하고 이 과정을 n번 반복해야 하므로 시간 복잡도는 O(n^2)이 된다.
선택 정렬 알고리즘
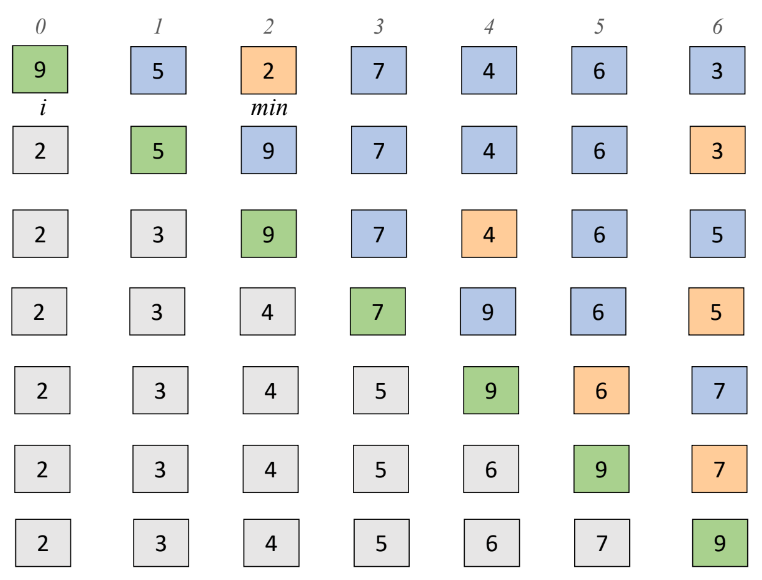
for (정렬 대상 집합에 원소가 남아 있을 경우):
집합에서 최솟값/최댓값 원소를 탐색한다.
기준 수와 탐색한 최솟값/최댓값 원소를 교환한다.
교환된 원소를 정렬 대상 집합에서 제외한다.
프로그램 8.1 최솟값 우선 선택 정렬
리스트의 왼쪽 수를 기준 수로 정하고 최솟값과 교환하는 과정을 반복한다.
리스트의 왼쪽에서 오른쪽으로 작은 수들이 채워져 나가면서 정렬이 진행된다.
class SelectionSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Selection Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def swap(self, a, b):
self.num[a], self.num[b] = self.num[b], self.num[a]
def sort(self):
n = self.size
for i in range(n-1):
min = i
for j in range(i+1, n):
if num[j] < num[min]:
min = j
self.swap(i, min)
print(self.num)
num = [31, 10, 9, 23, 49, 15, 11, 7]
s = SelectionSort(num)
s.sort()코드를 살펴보았다.
class SelectionSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Selection Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def swap(self, a, b):
self.num[a], self.num[b] = self.num[b], self.num[a]최솟값 우선 정렬의 바탕이 되는 함수들이다.
__init__ 함수에서 만들어질 때, 입력받은 num을 self.num으로, num 리스트의 길이를 size로 저장한 뒤 num 배열을 출력한다.
__str__ 함수에서 출력 형태를 지정한다. (예제에서 사용되지는 않는다.)
swap 함수에서 두 수의 위치를 바꾼다. 이는 최솟값을 찾았을 때 두 값의 위치를 바꾸는 용도로 사용된다.
def sort(self):
n = self.size
for i in range(n-1):
min = i
for j in range(i+1, n):
if num[j] < num[min]:
min = j
self.swap(i, min)
print(self.num)최솟값 정렬의 역할을 하는 sort() 함수이다.
리스트의 길이인 size를 n으로 입력받아 0부터 n-1까지 n개의 원소를 반복한다.
최솟값은 정렬하지 않은 리스트의 가장 앞 부분에 저장한다.
따라서 정렬하지 않은 리스트에서 최솟값은 비교하는 리스트의 가장 앞쪽의 인덱스의 값을 가진다.
최솟값인 i번째 인덱스를 제외하고 i+1번째 인덱스부터 n번째 인덱스를 비교하여 최솟값을 찾게 되면 값을 바꾼다.

8.3 버블 정렬
버블 정렬(bubble sort) : 리스트 왼쪽부터 인접한 원소들을 비교하여 큰 값(풍선)을 오른쪽으로 이동시키는 정렬 방법
오른쪽으로 이동한 최댓값은 정렬 과정에서 제외하고, 남은 원소들에 대해 이 과정을 반복한다.
원소들을 비교하여 최댓값을 오른쪽으로 이동시키는데 O(n)의 시간이 걸리고, 이 과정이 n번 반복되므로 시간 복잡도는 O(n^2)이 된다.
버블 정렬 알고리즘
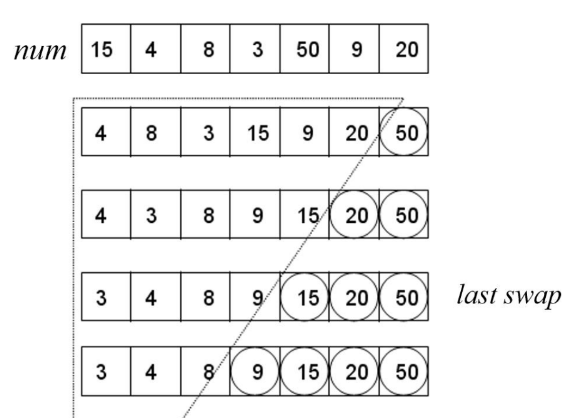
1. 리스트 왼쪽의 인접한 두 수를 비교하여 오름차순으로 정렬되도록 교환한다.
2. 오른쪽으로 1칸을 이동하여 같은 방식으로 두 수를 정렬하고 리스트 오른쪽 끝에 도달할 때까지 이 과정을 반복한다.
3, 최댓값이 오른쪽 끝에 도달하면 이 원소를 제외하고, 원소가 1개 남을 때까지 남은 원소들에 대해서 (1)번 과정부터 반복한다.
프로그램 8.2 버블 정렬
class BubbleSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Bubble Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def swap(self, a, b):
self.num[a], self.num[b] = self.num[b], self.num[a]
def sort(self):
n = self.size
for i in range(n-1):
flag = 0
for j in range(0, n-i-1):
if self.num[j] > self.num[j+1]:
self.swap(j, j+1)
flag = 1
if flag == 0: break
print(self.num)
num = [13, 25, 9, 12, 34, 52, 49, 17, 5, 8]
s = BubbleSort(num)
s.sort()코드를 살펴보았다.
버블 정렬의 바탕이 되는 함수들은 최솟값 정렬의 바탕 함수들과 같기 때문에 설명을 생락했다.
def sort(self):
n = self.size
for i in range(n-1):
flag = 0
for j in range(0, n-i-1):
if self.num[j] > self.num[j+1]:
self.swap(j, j+1)
flag = 1
if flag == 0: break
print(self.num)버블 정렬의 역할을 하는 sort() 함수이다.
리스트의 길이인 size를 n으로 입력받아 0부터 n-1까지 n개의 원소를 반복한다.
버블 정렬 여부를 확인하는 변수 flag를 선언한다.
버블 정렬은 최댓값을 오른쪽 끝에 저장하기 때문에 최댓값을 n-i-1번째 인덱스에 저장한다.
따라서 해당 인덱스에 도달할 때까지 현재 인덱스의 원소와 다음 인덱스의 원소를 비교하여 현재 인덱스가 더 크면 두 값을 바꾼다.
그리고 버블 정렬이 이루어졌다는 의미에서 flag를 1로 바꾼다.
버블 정렬이 도중에 일어나지 않았다는 것은 이미 정렬이 끝났다는 의미이다. 따라서 flag가 0이면 반복문을 더이상 실행하지 않는다.
정렬 이후 num 리스트를 출력한다.

8.4 삽입 정렬
삽입 정렬(insertion sort) : 정렬된 리스트에 새로운 원소를 추가하는 작업
정렬 대상에서 가장 왼쪽 1개 원소를 이미 정렬된 리스트로 사용한다.
이 정렬 리스트의 바로 옆 원소를 왼쪽으로 이동시켜서 올바른 위치에 삽입한다.
원소를 추가할 때마다 정렬 리스트의 크기가 1개씩 커지며, 모든 원소가 추가될 때까지 이 과정을 반복한다.
시간 복잡도는 이미 정렬이 완료되어 있는 최상의 경우에 O(n)이고, 원소들이 역순으로 되어 있는 최악의 경우에 O(n^2)이 된다.
삽입 정렬 알고리즘
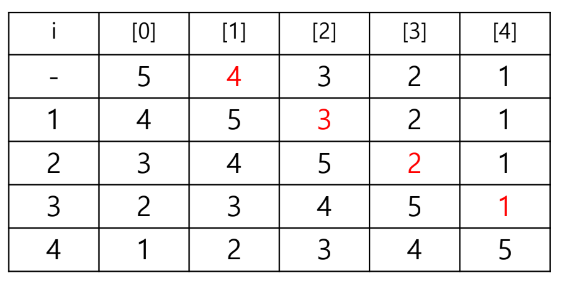
1. 주어진 리스트에서 첫 번째 항목은 이미 정렬이 완료된 리스트(S)이다.
2. 정렬 리스트(S)의 바로 오른쪽 원소가 정렬된 위치를 찾을 때까지 왼쪽으로 이동시킨다.
3. 정렬되지 않은 원소가 없을 때까지 (2)번 과정을 반복한다.
프로그램 8.3 삽입 정렬
class InsertionSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Insertion Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def swap(self, a, b):
self.num[a], self.num[b] = self.num[b], self.num[a]
def sort(self):
for i in range(1, self.size):
pivot = self.num[i]
j = i-1
while j >= 0 and pivot < self.num[j]:
self.num[j+1] = self.num[j]
j -= 1
self.num[j+1] = pivot
print(self.num)
num = [13, 25, 9, 12, 34, 52, 49, 17, 5, 8]
s = InsertionSort(num)
s.sort()코드를 살펴보았다.
삽입 정렬의 바탕이 되는 함수들은 최솟값 정렬의 바탕 함수들과 같기 때문에 설명을 생락했다.
def sort(self):
for i in range(1, self.size):
pivot = self.num[i]
j = i-1
while j >= 0 and pivot < self.num[j]:
self.num[j+1] = self.num[j]
j -= 1
self.num[j+1] = pivot
print(self.num)삽입 정렬의 역할을 하는 sort() 함수이다.
0번째 인덱스는 이미 정렬되었다고 여기기 때문에 1 ~ size-1번째 인덱스를 정렬한다.
pivot(기준수)를 num 리스트의 i번째 원소로 설정한다.
그리고 j를 통해 정렬된 리스트의 마지막 인덱스를 가리킨다.
정렬된 리스트의 인덱스가 0보다 크고, pivot이 j번째 원소보다 작은 동안 반복문으로 pivot의 오름차순 정렬에 해당하는 위치까지 올라간다.
그 뒤 j+1번째 리스트에 pivot을 입력해 원소를 삽입한 효과를 준다.
정렬이 완료된 뒤 출력하고, 모든 원소가 정렬될 때까지 이를 반복한다.

8.5 쉘 정렬
쉘 정렬(Shell sort) : 삽입 정렬의 성능을 개선하기 위한 알고리즘
인접한 원소들을 비교하기 때문에 작은 수가 리스트의 뒤쪽에 있을 때 정렬 위치를 찾을 때까지 비교 횟수가 많아진다.
쉘 정렬은 떨어져 있는 원소들 간에 삽입 정렬을 수해앟여 정렬 속도를 개선한다.
시간 복잡도는 삽입 정렬의 O(n^2)를 극복하여 평균적으로 O(n^3/2)의 시간이 소요된다.

쉘 정렬은 O(n^2)의 시간이 걸리는 버블 정렬, 삽입 정렬, 선택 정렬 알고리즘보다 성능이 우수한 것을 알 수 있다.
그러나 원소 수가 5000개가 넘는 시점부터 처리 시간이 증가하며, 알고리즘이 다소 복잡하다는 단점이 있다.
쉘 정렬 알고리즘

1. 정렬할 원소의 수가 n개일 때, 비교할 원소 간의 거리를 gap이라고 정의한다.
2. gap이 홀수가 되도록 n/2 또는 (n/2)+1로 계산한다.
3. gap만큼 떨어져 있는 원소들 간에 삽입 정렬을 수행한다.
4. gap이 1보다 크면 (2)번 과정부터 반복하고, gap이 1에 도달하면 종료한다.
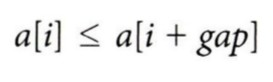
쉘 정렬은 각 단계 수행 후 원소들 간에 위의 관계가 성립한다.
프로그램 8.4 쉘 정렬
# 쉘 정렬
class ShellSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Shell Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " % self.num[i])
def sort(self):
global prev
n = self.size
gap = n // 2
while gap > 0:
if gap % 2 == 0: gap += 1
for i in range(gap, n):
h = 0
while gap * h + i < n:
j = gap * h + i
temp = self.num[j]
while j >= gap:
if temp < self.num[j-gap]:
self.num[j] = self.num[j-gap]
else: break
j -= gap
self.num[j] = temp
h += 1
if self.num != prev:
print(gap, self.num)
prev = self.num[:]
gap //= 2
print()
num = [38, 32, 17, 5, 18, 25, 12, 7, 2]
#num = [77, 62, 14, 9, 30, 21, 80, 25, 70, 55]
prev=[]
s = ShellSort(num)
s.sort()코드를 살펴보았다.
쉘 정렬의 바탕이 되는 함수들은 최솟값 정렬의 바탕 함수들과 같기 때문에 설명을 생락했다.
def sort(self):
global prev
n = self.size
gap = n // 2
while gap > 0:
if gap % 2 == 0: gap += 1
for i in range(gap, n):
h = 0
while gap * h + i < n:
j = gap * h + i
temp = self.num[j]
while j >= gap:
if temp < self.num[j-gap]:
self.num[j] = self.num[j-gap]
else: break
j -= gap
self.num[j] = temp
h += 1
if self.num != prev:
print(gap, self.num)
prev = self.num[:]
gap //= 2
print()쉘 정렬의 역할을 하는 sort() 함수이다.
처음에 보면 헷갈리기 때문에 예제의 gap의 변화에 따라 수의 정렬도 함께 살펴보면서 이해해보자. 할 수 있다!
반복문을 거치기 전의 리스트 값을 담는 prev 리스트를 선언한다.
size를 입력받아 2로 나눠 gap을 구한다. 예제 리스트의 개수가 9이기 때문에 gap은 4인데, gap은 홀수여야 하기 때문에 +1해서 5이다.
반복문으로 i가 gap(5) ~ 8까지를 반복하고, h를 1로 초기화한다.
j를 i * h의 값을 가지도록 하고, temp에 num[i*h]번째 값을 넣는다. 예제에서는 5~8의 값이 순서대로 들어간다.
j가 gap보다 크거나 같은 동안 temp의 값이 num의 [j-gap]보다 작다면 두 수의 값을 바꾼다.
h += 1로 인해 h = 2가 되어서 gap(5) * h(2) + i는 i의 값에 상관없이 n(9)보다 커지기 때문에 반복문이 끝난다.
gap /= 2 로 인해 gap = 2 + 1 = 3이 된다.
| i = 5, 38(0) ↔ 25(5) i = 6, 32(1) ↔ 12(6) i = 7, 17(2) ↔ 7(7) i = 8, 5(3) ↔ 2(8) |
 |
gap(3)이 i가 gap(3) ~ 8까지를 반복하고, h를 1로 초기화한다.
i = 6부터는 이미 정렬되었기 때문에 출력을 거치지 않고 넘어간다.
h += 1로 인해 h = 2가 되어서 gap(3) * h(2) + i는 i의 값에 상관없이 n(9)보다 커지기 때문에 반복문이 끝난다.
gap /= 2 로 인해 gap = 1이 된다.
| i = 3, 25(0) ↔ 2(3) i = 4, 18(4) ↔ 17(7) i = 5, 38(5) ↔ 5(8), 7(2) ↔ 5(5) |
 |
gap(1)이 i가 gap(1) ~ 8까지를 반복하고, h를 1로 초기화한다.
한 칸씩 정렬을 거치며 정돈한다.
gap /= 2로 인해 gap = 0이 되어 반복을 종료한다.
| i = 1 i = 2, 12(1) ↔ 5(2) i = 3 i = 4, 25(3) ↔ 17(54) i = 5, 12(2) ↔ 17(3) ↔ 25(4) ↔ 7(5) i = 6 i = 7, 25(5) ↔ 32(6) ↔ 18(7) i = 8 |
 |

8.6 퀵 정렬
퀵 정렬(quick sort) : 기준 수(pivot)를 선택하여 정렬할 원소들을 pivot값보다 작은 세그먼트와 큰 세그먼트로 분할하는 방식
분할이 완료되면 pivot은 두 세그먼트 사이로 이동한다.
양쪽의 각 세그먼트는 재귀적으로 퀵 정렬을 적용하여 전체 정렬을 완료한다.
재귀적 퀵 정렬은 세그먼트에 더 이상 정렬할 원소가 없으면 종료된다.
퀵 정렬의 평균 정렬 속도는 O(nlogn)으로 이전에 배운 정렬 알고리즘보다 빠른 편이다.
이는 퀵 정렬의 리스트 분할에 걸리는 시간 복잡도O(n)과 n개의 레벨을 탐색하는데 걸리는 시간 O(logn)의 곱이다.
그러나 분할 결과가 세그먼트 1은 size 0, 세그먼트 2는 size n-1과 같은 한쪽 세그먼트로 계속해서 원소가 몰리는 최악의 경우에는 시간 복잡도가 O(n^2)이 되어 정렬 속도가 떨어진다.
퀵 정렬 알고리즘
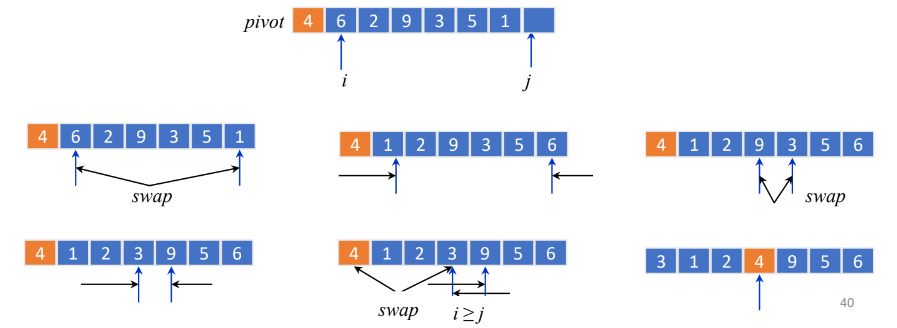
1. 리스트의 가장 왼쪽 원소를 기준 수(pivot)로 지정하여 pivot보다 작은 세그먼트와 큰 세그먼트로 리스트를 분할한다.
더 이상 분할이 일어나지 않으면 종료한다.
2. pivot은 분할된 두 세그먼트 사이로 옮긴다.
3. 각 세그먼트를 퀵 정렬 알고리즘으로 정렬한다.
퀵 정렬의 리스트 분할 알고리즘

1. 기준수(x)는 리스트의 가장 왼쪽 수로 정하고, x의 오른쪽 옆을 i로, 리스트의 가장 오른쪽 끝을 j로 지정한다.
2. x보다 큰 값을 찾을 때가지 i를 오른쪽으로 이동시키고, x보다 작은 값을 찾을 때까지 j를 왼쪽으로 이동시킨다.
3. 과정 (2)를 수행 후
3-1. i < j일 경우, i와 j 위치의 원소를 교환한 후 과정 (2)를 반복한다.
3-2. i >= j이면 분할이 완료되었으므로 기준수(x)와 j 위치 원소와 교환한 후 종료한다.

퀵 정렬을 재귀적으로 반복해서 정렬을 수행한 모습이다.
프로그램 8.5 퀵 정렬
class QuickSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Quick Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def swap(self, a, b):
self.num[a], self.num[b] = self.num[b], self.num[a]
def sort(self, left, right):
if left < right:
i = left
j = right + 1
pivot = num[left]
while True:
while True:
i += 1
if i > right or self.num[i] >= pivot: break
while True:
j -= 1
if j < left or self.num[j] <= pivot: break
if i < j:
self.swap(i, j)
print(self.num)
else: break
self.swap(left, j)
if left != j: print(self.num)
self.sort(left, j - 1)
self.sort(j + 1, right)
num = [13, 25, 9, 12, 34, 52, 49, 17, 5, 8]
s = QuickSort(num)
s.sort(0, len(num) - 1)코드를 살펴보았다.
퀵 정렬의 바탕이 되는 함수들은 최솟값 정렬의 바탕 함수들과 같기 때문에 설명을 생락했다.
def sort(self, left, right):
if left < right:
i = left
j = right + 1
pivot = num[left]퀵 정렬의 역할을 하는 sort() 함수이다.
리스트의 시작과 끝 값 start, end를 입력받는다.
pivot은 리스트의 첫 번째 값을 가진다.
i는 리스트의 첫 번째 원소, j는 리스트의 마지막 원소보다 1 큰 값을 가진다.
이는 반복문이 시작하자마자 i+1, j-1이 실행되기 때문에 시작점은 원소-1, 끝점은 원소+1이어야 전체를 확인할 수 있기 때문이다.
while True:
while True:
i += 1
if i > right or self.num[i] >= pivot: break첫 번째 반복문은 i와 j의 값을 비교하는 퀵 정렬의 partition을 위함이다.
두 번째 반복문에서 시작점부터 i에 +1을 하면서 값을 비교한다.
순환을 끝냈는데 해당하는 값이 없거나 pivot보다 큰 값을 찾았다면 반복문을 멈춘다.
while True:
j -= 1
if j < left or self.num[j] <= pivot: breakj도 마찬가지로 끝에서부터 j에 -1을 하면서 값을 비교한다.
순환을 끝냈는데 해당하는 값이 없거나 pivot보다 작은 값을 찾았다면 반복문을 멈춘다.
if i < j:
self.swap(i, j)
print(self.num)
else: break만약 i < j라면 두 원소의 자리를 바꾸고 그 결과를 출력한다.
그렇지 않고 i >= j라면 반복문을 멈춘다.
self.swap(left, j)
if left != j: print(self.num)
self.sort(left, j - 1)
self.sort(j + 1, right)left와 j의 값을 바꿔서 pivot을 가운데에 들어가도록 바꾼다.
left와 j의 값이 같다는 뜻은 재귀함수에 들어간 값이 1개라는 뜻이므로 더 이상 정렬할 필요가 없다.
pivot을 기준으로 오른쪽과 왼쪽으로 재귀적으로 정렬해 전체 값을 정렬하도록 한다.

8.7 합병 정렬
합병 정렬(merge sort) : 정렬된 리스트들을 하나로 합치는 합병(merge) 작업을 활용하는 알고리즘
합병 과정은 정렬된 2개의 서브 리스트를 하나로 합치는 것으로, 최솟값 원소끼리 비교하여 더 작은 값을 먼저 정렬 리스트로 이동하는 작업을 반복한다.
n개의 원소를 분할하는데 걸리는 시간은 O(n)이다.
그리고 한 레벨에 있는 모든 세그먼트를 합병하는데 걸리는 시간은 O(n)이고 레벨 수가 logn개이므로, 합병 작업에 필요한 총 시간은 O(nlogn)이 된다.
분할과 합병 시간을 합치면 O(n) + O(nlogn)이지만 빠르게 증가하는 항을 선택하면 합병 정렬의 시간 복잡도는 O(nlogn)이 된다.
합병 정렬 알고리즘
1. 리스트를 반으로 나누어 2개의 세그먼트로 분할한다.
2. 분할된 각 세그먼트를 합병 정렬 알고리즘으로 정렬한다.
3. 정렬된 두 세그먼트를 합병하여 정렬을 완료한다.
합병 정렬에서 (1)번 과정은 세그먼트에 대한 재귀적인 분할이 더 이상 발생하지 않는 시점에 종료된다.
프로그램 8.6 합병 정렬
class MergeSort:
def __init__(self, num):
self.num = num
self.size = len(num)
print("Merge Sort", self.num)
def __str__(self):
for i in range(self.size):
print("%2d " %self.num[i])
def mergesort(self, left, right):
if right > left:
mid = (left + right) // 2
self.mergesort(left, mid)
self.mergesort(mid + 1, right)
self.merge(left, mid + 1, right)
print(self.num)
def merge(self, left, mid, right):
pos = left
left_end = mid - 1
n = right - left + 1
temp = [None] * self.size
while left <= left_end and mid <= right:
if self.num[left] <= self.num[mid]:
temp[pos] = self.num[left]
pos = pos + 1
left = left + 1
else:
temp[pos] = self.num[mid]
pos = pos + 1
mid = mid + 1
while left <= left_end:
temp[pos] = self.num[left]
left = left + 1
pos = pos + 1
while mid <= right:
temp[pos] = self.num[mid]
mid = mid + 1
pos = pos + 1
for i in range(n):
self.num[right] = temp[right]
right = right - 1
num = [40, 15, 34, 29, 3, 10, 9, 17, 37]
s = MergeSort(num)
s.mergesort(0, len(num) - 1)코드를 살펴보았다.
합병 정렬의 바탕이 되는 함수들은 최솟값 정렬의 바탕 함수들과 같기 때문에 설명을 생락했다.
def mergesort(self, left, right):
if right > left:
mid = (left + right) // 2
self.mergesort(left, mid)
self.mergesort(mid + 1, right)
self.merge(left, mid + 1, right)
print(self.num)합병 병렬 이전에 원소를 분할하는 역할을 하는 mergesort() 함수이다.
right가 left보다 크다는 것은 원소가 2개 이상이라는 의미이다.
따라서 right = left(원소가 1개)가 될 때까지 재귀를 이용해서 left 세그먼트와 right 세그먼트로 나눈다.
각각의 세그먼트 원소가 1개가 되었다면 merge 함수를 이용해서 합병한다.
def merge(self, left, mid, right):
pos = left
left_end = mid - 1
n = right - left + 1
temp = [None] * self.size분할된 원소를 합병하는 merge() 함수이다.
시작값 left, 중간값 mid(입력할 때는 mid+1), 끝값 right를 입력바당 실행한다.
pos에 시작값 left를 저장하고 left_end에 합병할 두 세그먼트 중 left 세그먼트의 마지막 값인 mid-1(원래는 mid)를 저장한다.
n에는 right - left + 1로 합병 이후 리스트 원소의 개수를 저장한다.
정렬할 원소를 저장할 리스트 temp는 빈 상태로 초기화한다.
while left <= left_end and mid <= right:
if self.num[left] <= self.num[mid]:
temp[pos] = self.num[left]
pos = pos + 1
left = left + 1
else:
temp[pos] = self.num[mid]
pos = pos + 1
mid = mid + 1left <= left_end라는 뜻은 left 세그먼트에 원소가 존재한다는 뜻이고, 마찬가지로 mid <= right는 right 세그먼트에 원소가 존재한다는 뜻이다.
두 세그먼트에 원소가 존재하는 동안 두 세그먼트를 비교해 작은 수를 temp로 이동한다.
if 문은 left 세그먼트가 작을 경우, else문은 right 세그먼트가 작을 경우 실행된다.
temp의 인덱스 post를 +1 하고, left 혹은 right 세그먼트의 인덱스인 left/mid를 알맞게 증가시킨다.
두 세그먼트 중 원소가 없는 세그먼트가 생기면 반복문이 끝난다.
while left <= left_end:
temp[pos] = self.num[left]
left = left + 1
pos = pos + 1
while mid <= right:
temp[pos] = self.num[mid]
mid = mid + 1
pos = pos + 1첫번째 while문은 left 세그먼트에 원소가 남았다면 이를 temp에 옮긴다.
두번째 while문은 right 세그먼트에 원소가 남았다면 이를 temp에 옮긴다.
두 while문 중 한 가지만 실행된다.
for i in range(n):
self.num[right] = temp[right]
right = right - 1반복문을 이용해 temp를 num 리스트에 복사한다.
left와 mid는 합병을 하는 과정에서 값을 변경시켰기 때문에 right를 이용해서 복사한다.

Bonus 1. 자연 합병 정렬
자연 합병 정렬(natural merge sort) : 합병 정렬 중 일부는 이미 정렬이 되어 있는 리스트를 합병 정렬하는 방법
ex) input = [8, 9, 10, 2, 5, 7, 9, 11, 13, 15, 6, 12, 14]
위의 input을 a[i] > a[i+1]을 기준으로 분할한다.
→ [8, 9, 10], [2, 5, 7, 9, 11, 13, 15], [6, 12, 14]
합병 정렬을 사용하면 input을 4번 분할해야 하지만, 자연 합병 정렬을 이용하면 input을 2번만 분할하고도 정렬을 할 수 있다.
Bonus 2. 기수 정렬
기수 정렬(radix sort) : 자릿수를 기준으로 정렬하는 방법
1. 비교(LSD→MSD)
2. 분배
3. 합병
기수 정렬의 시간 복잡도는 기수 정렬 원소의 최대 자릿수가 k, key의 개수가 n일 때 O(k*n)의 값을 갖는다.
기수 정렬은 key끼리 비교하지 않기 때문에 비-비교정렬(non-comparative integer sorting algorithm)으로 분류된다.
그 외 다른 알고리즘은 모두 key끼리 대소관계를 비교하기 때문에 비교정렬(comparative sorting algorithm)이다.
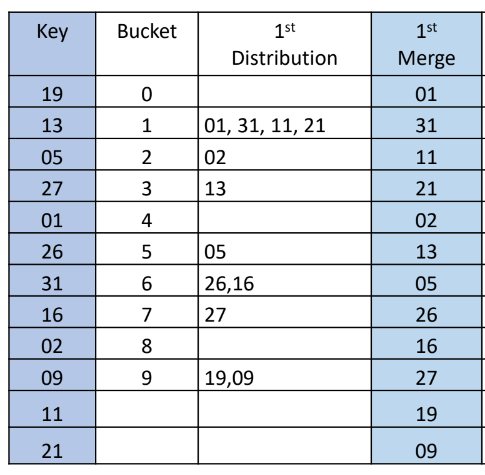
key = [19, 13, 5, 27, 1, 26, 31, 16, 2, 9, 11, 21]를 기수정렬을 이용해서 정렬하는 방법
 |
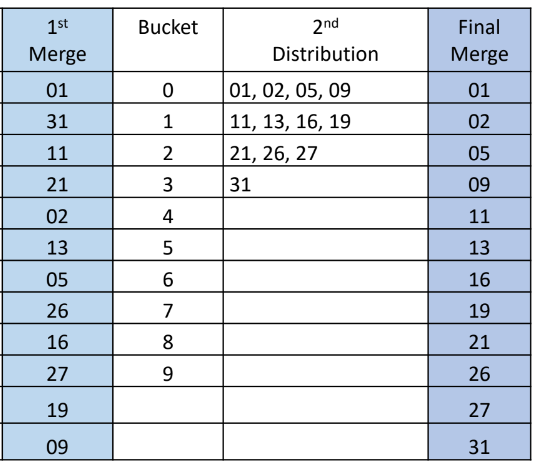 |
| LSD 낮은 자릿수(1의 자리)를 기준으로 정렬한다. |
MSD 그 다음으로 낮은 자릿수(10의 자리)를 기준으로 정렬한다. 정렬하는 원소가 2자리이기 때문에 종료된다. |
Bonus 3. 알고리즘 시간 복잡도 비교
| 알고리즘 | 평균 시간복잡도 (average time) | 최악 시간복잡도 (worst case time) |
| 선택 정렬(selection sort) |  |
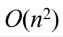 |
| 버블 정렬(bubble sort) |  |
 |
| 삽입 정렬(insertion sort) |  |
 |
| 쉘 정렬(quick sort) | 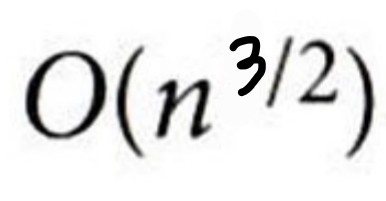 |
 |
| 퀵 정렬(quick sort) |  |
 |
| 합병 정렬(merge sort) | 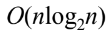 |
 |
| 기수 정렬(radix sort) |  |
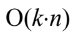 |