
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- backjoon
- python
- htmlinjection
- pwnable
- Systemhacking
- Dreamhack
- beebox
- 백준
- bWAPP
- Reflected
- Reversing
- S3
- cloud
- 자료구조
- SISS
- Linux
- basicrce3
- datastructure
- mount
- wireshark
- AWS
- 와이어샤크
- 유석종교수님
- CodeEngn
- EC2
- Upstage
- System
- c
- acc
- fork-bomb
- Today
- Total
Ctrl + Shift + ESC
CHAPTER 02 파이썬 자료구조 본문
2.1 파이썬 언어의 특징
1. 파이썬은 인터프리터(interpreter) 방식의 언어이다.
- 컴파일 과정 없이 문장 단위로 빠르게 실행과 테스트가 가능하다.
2. 파이썬은 객체 지향(object-oriented) 언어이다.
- 클래스를 통하여 객체의 속성과 메소드를 정의하여 인간의 사고와 유사하게 고급 수준의 프로그램을 작성할 수 있다.
3. 파이썬은 동적 타이핑(dynamic typing) 언어이다.
- C언어와 달리, 변수의 자료형을 선언할 필요 없이 변수에 값이 할당되는 순간 자료형이 결정된다.
4. 리스트, 집합, 딕셔너리 등 군집 자료형 기능이 우수하다.
- 리스트, 집합, 딕셔너리 등 시퀀스 자료형과 군집 자료형 지원 기능이 우수하다.
5. 파이썬 변수는 값(리터럴)에 대한 참조이다.
- 불변 자료형 변수에 대해서 참조에 의한 호출(call by reference)를 지원하지 않고 return 문이나 클래스 객체 변수를 통해 변한 값을 전달한다.
6. 파이썬은 배열 대신 리스트를 사용한다.
- 배열과 같이 원소 크기를 미리 지정하는 정적 할당(static allocation)이 아니라 리스트에 원소를 추가할 때마다 크기가 변하는 동적 할당
(dynamic allocation) 방식이다.
2.2 파이썬의 자료형
시퀀스 자료형(sequence data type)에는 리스트, 튜플, 문자열이 있으며, 군집 자료형(collection data type)으로 집합과 딕셔너리가 있다.
|
자료형
|
종류
|
|
불 형(bool type)
|
불리언(True, False)
|
|
수치 형(numericcal type)
|
정수(int), 실수(float), 복소수(complex)
|
|
시퀀스 형(sequence type)
|
리스트(list), 튜플(tuple), 문자열(string)
|
|
군집 형(collection type)
|
집합(set), 딕셔너리(dictionary)
|
리스트 : https://wikidocs.net/53
1.3 리스트(list)
* 강의 영상: [https://youtu.be/-BA3lbvggCM](https://youtu.be/-BA3lbvggCM) 안녕하세요~ 여러분~ 오늘도 여러분과 함 ...
wikidocs.net
문자열과 리스트 : https://wikidocs.net/70
4.2 문자열과 리스트
문자열과 리스트를 좀 더 자세히 알아봅시다. ### 문자열 문자열에서는 요런 식으로 한 글자마다 번호를 매긴답니다. 문자열을 만들어서 이것저것 시켜보세요. ...
wikidocs.net
딕셔너리 : https://wikidocs.net/72
4.4 딕셔너리(dict)
오늘 제가 여러분과 함께 공부할 것은 딕셔너리 자료형이예요. 사전을 한번도 못 보신 분은 안 계시죠? **dictionary** n. pl. dictionaries ...
wikidocs.net
프로그램 2.1) 파이썬 자료형
파이썬에서 지원하는 자료형을 type() 함수를 이용해서 종류별로 출력해보자.
# 파이썬 자료형의 종류
i = 7
f = 100.5
c = 's'
s = 'python'
x = 3 + 5j
b = True
lst = [2, 3, 5, 7, 11]
tpl = (1, 3, 5, 7, 9)
set1 = {10, 20, 30, 40, 50}
dic = {'02':'서울', '051':'부산', '053':'대구', '032':'인천'}
print(type(i))
print(type(f))
print(type(c))
print(type(s))
print(type(x))
print(type(b))
print(type(lst))
print(lst)
print(type(tpl))
print(tpl)
print(type(set1))
print(set)
print(type(dic))
print(dic)
프로그램 2.2) 팩토리얼
2부터 20까지 각 수의 팩토리얼(factorial)을 계산하는 프로그램을 작성해 보자.
fact(n)은 반복문으로 n!을 계산하여 결과 값을 반환하는 함수이다.
변수(i)의 값을 변경하여 파이썬에서 팩토리얼 계산이 가능한 수의 범위를 확인해 보자.
def fact(n):
total = 1
for j in range(2, n+1) :
total = total * j
return total
i = 20
for n in range(2, i+1) :
print(n, "!=", fact(n))
2.3 파이썬의 변수
파이썬에서 변수는 대상 값(리터럴)에 대한 참조(reference)이다.
리터럴(literal) : 변수가 참조하는 값, 변수는 직접 값을 저장하지 않고 값이 저장된 잠소를 참조한다.
이와 같은 특성을 활용하면 두 변수 값을 교환하는 작업을 a, b = b, a와 같은 간단한 명령문으로 처리할 수 있다.
파이썬 자료형은 불변 자료형(immutable data type)과 가변 자료형(mytable data type)으로 나뉜다.
프로그램 2.3) 불변 자료형
불변 자료형 : 원래 값의 변경이 불가능하다. 정수(int), 실수(float), 문자열(string)이 있다.
# 불변 자료형
a = 2
b = a
print("a", a, id(a))
print("b", b, id(b))
b = b + 1
print("a", a, id(a))
print("b", b, id(b))위의 프로그램은 변수 a와 b가 같은 값을 참조한 뒤 b의 값을 변경하는 내용이다.
만약 b의 값을 변경하면, b는 새로 생성된 리터럴(3)을 가리키게 되고 변수 a가 참조하는 값에는 변화가 없다.

id()는 변수가 참조하는 객체의 주소를 반환하는 함수이다.
변수 b의 값을 변경한 후 id() 함수의 반환 값을 보면 새로운 객체를 참조하고 있음을 알 수 있다.
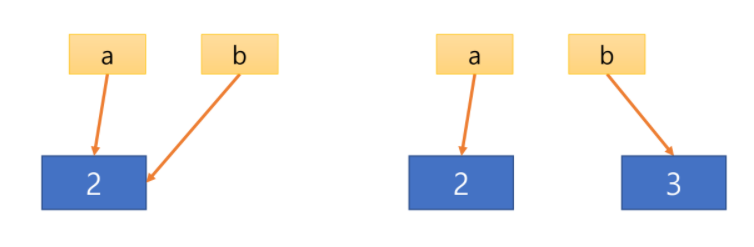
그림과 같이 불변 자료형의 원래 값은 변경할 수 없으며 변경 작업은 새로운 값을 생성하게 된다.
리터럴은 그것을 참조하는 변수가 더 이상 없으면 소멸된다.
이와 같은 특성 때문에 불변 자료형 변수를 함수에 매개 변수로 전달하면 참조에 의한 호출(call by reference) 방식으로 값을 수정할 수 없다.
그러나, 파이썬에서는 몇 가지 대안을 지원하고 있으며 차후 배우게 된다.
프로그램 2.4) 가변 자료형
가변 자료형 : 원소의 값을 수정할 수 있다. 리스트와 딕셔너리와 같은 군집 자료형이 포함된다.
리스트는 참조 변수들의 모음이며, 함수에 전달하여 참조에 의한 호출 방식으로 원소를 변경할 수 있다.
# 가변 자료형
A = [2, 3, 4]
B = A
print("A", A, id(A))
print("B", B, id(B))
B.append(5)
print("A", A, id(A))
print("B", B, id(B))
리스트에 원소를 추가한 후에도 리스트 주소에 변화가 없는 것을 알 수 있다.
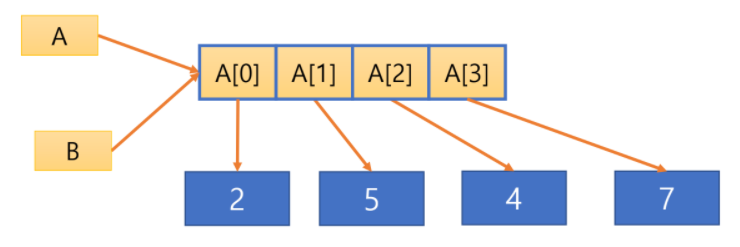
그림과 같이 위 프로그램을 실행한 후의 결과로 리스트 A와 B가 동일한 원소들을 참조하고 있다.
프로그램 2.5) 불변 자료형 변수를 함수에 전달
리스트와 딕셔너리는 함수에서 참조에 의한 호출을 통해 수정이 가능하다.
하지만 불변 자료형에 대해서는 이 방법을 지원하지 않기 때문에 반환문(return), global 키워드, 그리고 객체의 멤버 변수를 이용해야 한다.
# 매개변수 전달
def f(a) :
a = 3
print(a)
return a
b = 2
f(b)
print(b)
b = f(b)
print(b)위의 프로그램은 함수의 반환문을 통해 불변 자료형 변수의 값을 변경하는 예이다.

b의 원래 값은 2였지만, f() 함수에 b를 매개변수로 전달해서 b의 값을 3으로 바꿔서 출력하고, 3을 반환한다.
여기서 f(b)의 값이 3이지 b의 값은 여전히 2이다. 혼동하지 않도록 주의하자.
b = f(b)를 통해 b의 값을 f(b)의 반환값, 즉 3으로 변경하고 print(a)를 통해 3을 출력한다.
변경한 뒤의 값은 3으로 잘 변경된 것을 확인할 수 있다.
프로그램 2.6) 주사위 던지기
주사위를 던져서 각 눈이 나오는 비율을 계산하는 예제이다.
throw_dice() 함수에 전달된 리스트(dice)의 원소 값을 변경한 후 전달한다.
# 주사위 던지기 (함수에 리스트 전달)
import random
def throw_dice(count, n) :
for i in range(n) :
eye = random.randint(1,6)
count[eye-1] += 1
def calc_ratio(count) :
ratio = []
total = sum(count)
for i in range(6) :
ratio.append(count[i] / total)
return ratio
def print_percent(num) :
print("[", end = '')
for i in num :
print("%4.2f" % i, end = ' ')
print("]")
dice = [0] * 6
for n in [10, 100, 1000] :
print("Times =", n)
throw_dice(dice, n)
print(dice)
ratio = calc_ratio(dice)
print_percent(ratio)
print()코드를 살펴보았다.
dice = [0] * 6
for n in [10, 100, 1000] :
print("Times =", n)
throw_dice(dice, n)dice는 여섯 면이기 때문에 [0] * 6으로 여섯 면을 만든다.
각각 10번, 100번, 1000번을 실행해 각 면이 나온 비율을 계산할 것이다.
print를 통해 횟수를 출력하고 throw_dice 함수를 실행한다.
def throw_dice(count, n) :
for i in range(n) :
eye = random.randint(1,6)
count[eye-1] += 1
print(dice)매개변수를 입력받은 횟수만큼 반복문을 통해 1에서 6 사이의 랜덤 정수를 얻는다.
count 리스트(매개변수로 입력받았으니 dice 리스트)의 랜덤 정수-1 칸에 (0부터 시작하기 때문) 횟수를 1 더한다.
반복문이 완료되면 dice 리스트에 저장된 값을 출력한다.
ratio = calc_ratio(dice)
def calc_ratio(count) :
ratio = []
total = sum(count)
for i in range(6) :
ratio.append(count[i] / total)
return ratioratio(비율)을 알아보기 위해서 함수 calc_ratio를 실행한다.
각 비율을 저장할 리스트 ratio를 만들어 놓고 전체 횟수를 구하기 위해 각각의 횟수를 전부 더한다.
반복문을 통해 각 횟수를 전체 횟수로 나누는 것을 6번 반복하고 비율을 저장한 리스트 ratio를 반환한다.
print_percent(ratio)
def print_percent(num) :
print("[", end = '')
for i in num :
print("%4.2f" % i, end = ' ')
print("]")
print()퍼센테이지를 일정한 규격으로 출력하기 위해 print_percent 함수를 실행한다.
print_percent 함수는 리스트 출력 형태로 실수형을 소수점 두번째 자리까지 출력한다.
다음 함수와 구별하기 좋게 줄바꿈을 추가한다.

프로그램 2.7) 별명
별명(alias) : 두 변수가 하나의 객체를 동시에 참조하여 공유하는 것
A = [[2, 3, 4], 5]
B = A
B[0][1] = 'f'
print(A, id(A))
print(B, id(B))
위의 프로그램에서 두 변수 A와 B는 같은 리스트 객체를 참조하고 있는 별명 관계이다.
이 중 B를 수정한 후 공유하고 있는 대상 객체가 변경된 것을 확인할 수 있다.
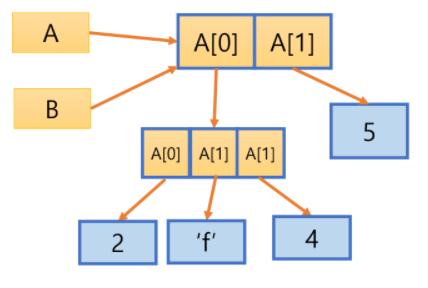
위 그림에 이 상황에 대한 개념도가 나타나 있다.
프로그램 2.8) 얕은 복사
얕은 복사(shallow copy) : 변수는 복사하여 새로 생성하지만 참조하는 리터럴은 공유하는 복사 방법
얕은 복사는 다음과 같이 copy 모듈의 copy() 함수를 사용하여 실행한다.
B = copy.copy(A)위의 문장은 B = list(A)와 동일한 효과를 갖는다.
# 얕은 복사
import copy
A = [[2, 3, 4], 5]
B = copy.copy(A) # B = list(A)
B[0][1] = 'f'
B[1] = 7
print(A, id(A), id(A[0]), id(A[0][1]))
print(B, id(B), id(B[0]), id(B[0][1]))위의 프로그램을 보면 리스트 A를 변수 B에 얕은 복사한다.
얕은 복사를 통해 리스트 B의 원소들은 새롭게 생성되지만, 원소들이 참조하는 객체는 원본과 동일하며 새로 생성되지 않는다.

실행 결과를 보면 리스트 A와 B의 주소는 다르지만 리스트 원소가 참조하는 객체는 동일하다.
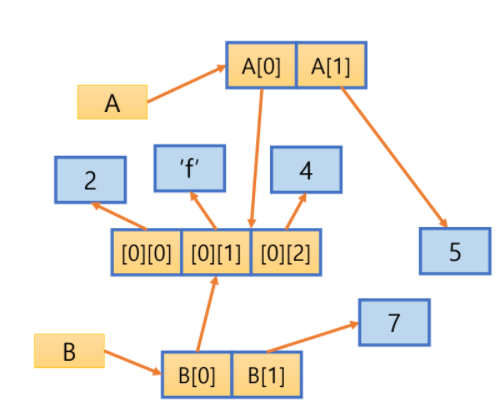
위 그림에 이 상황에 대한 개념도가 나타나 있다. 설명을 조금 덧붙여 보았다.
B[0][1] = 'f'
B[1] = 7이 두 줄의 코드에서 B[0][1]은 얕은 복사가 되어 참조하는 리터럴이 같기 때문에 B의 값을 변화하면서 A의 값도 함께 변화되었다.
하지만 B[1]은 B의 값을 바꿨지만 A의 값이 변하지 않았다.
이 점에서 헷갈릴 수 있을 것 같다.
여기서 주목해야 할 점은 B[0][1]은 리스트이므로 가변 자료형이고, B[1]은 int이므로 불변 자료형이다.
가변 자료형은 값을 변경할 때 값을 바꾼다. 따라서 B[0][1]의 값을 직접 바꾸고, 이로 인해 같은 곳을 참조하고 있는 A도 함께 바뀐다.
불변 자료형을 값을 변경할 때 참조 위치를 바꾼다. 원래는 B[1]도 5를 가리키고 있었지만, 값을 7로 바꾸면서 직접 값을 바꾸는 것이 아니라 참조하는 위치를 바꾼다. 따라서 A는 참조하는 위치가 바뀔 이유가 없기에 그대로 5를 참조하고, B는 바뀐 7을 참조하면서 참조 위치가 달라진다.
# 얕은 복사
import copy
A = [[2, 3, 4], 5]
B = copy.copy(A) # B = list(A)
B[0][1] = 'f'
B[1] = 7
print(A, id(A), id(A[1]), id(A[0][1]))
print(B, id(B), id(B[1]), id(B[0][1]))코드를 살짝 바꿔서 id(A[1])과 id(B[1])을 비교해 보자.

참조 위치가 달라진 것을 확인할 수 있다.
프로그램 2.9) 깊은 복사
깊은 복사(deep copy) : 변수와 대상 객체(리터럴)를 모두 복제하여 생성하는 것

위 그림은 리스트 A를 복제한 리스트 B가 변수와 대상 객체를 모두 복제하여 생성된 모습을 표현한다.
# 깊은 복사
import copy
A = [[2, 3, 4], 5]
B = copy.deepcopy(A)
B[0][1] = 'f'
B[1] = 7
print(A, id(A), id(A[0]), id(A[0][1]), id(A[1]))
print(B, id(B), id(B[0]), id(B[0][1]), id(B[1]))위의 프로그램에서 B는 깊은 복사로 만들어진 변수이다.
변수 A와 B, 리스트 원소, 그리고 원소가 참조하는 객체의 주소가 모두 다르다는 사실로 알 수 있다.
리스트 원소가 참조하는 객체도 복제되기 때문에 B의 원소 값을 수정해도 리스트 A가 참조하는 객체에는 변화가 없다.

B의 값만 변화하고, A와 B의 주소가 전부 다른 것을 확인할 수 있다.
[python] 파이썬 얕은복사, 깊은복사 (copy, deepcopy, [:], =) 총 정리
안녕하세요. BlockDMask입니다. 오늘은 파이썬 얕은 복사, 깊은 복사에 대해서 정리해보려 합니다. 은근히 헷갈려서 천천히 한번 정리해볼게요. <목차> 1. 파이썬 얕은 복사 2. 파이썬 깊은 복사 3. 그
blockdmask.tistory.com
2.4 리스트
C언어에서 사용하는 정적 배열(array)은 고정된 개수의 원소들이 나열되어 있는 자료형으로, 선언한 이후에는 배열 크기 변경이 불가능하다.
정적 배열은 각 원소 공간에 값이 직접 저장되며 인덱스로 원소 값에 접근한다.

파이썬은 정적 배열을 지원하지 않으며 대신 리스트를 사용한다.
리스트 원소는 값(리터럴)에 대한 참조 변수이며 참조 대상의 자료형이 동일할 필요는 없다.
또한 리스트 크기는 원소의 추가 또는 삭제에 의해 동적으로 변경된다.
A = [2, 3, 4]
A.append(7)
A[1] = 9
위의 그림은 명령문이 실행한 후의 리스트 구조이다.
A[1]이 참조하는 리터럴(9)은 기존 값(3)이 변경된 것이 아니라 새로 생성된 것이다.
여기서 아까 배운 내용과 혼동이 올 수 있는데, 지금 리스트가 참조하는 리터럴은 int형 불변 자료형이다.
따라서 값을 바꾸기 위해서는 참조 위치를 바꿔야 한다.
프로그램 2.10) 리스트의 생성
리스트는 다음의 세 가지 방법으로 생성할 수 있다.
1. 리스트 복합 표현(list comprehension)
2. range()와 list() 함수 사용
3. 빈 리스트 선언 후 원소 추가
# 리스트의 생성
num1 = [i for i in range(10)]
num2 = list(range(10))
num3 = []
for i in range(10):
num3 = num3 + [i] #num3.append(i)
print('num1', num1)
print('num2', num2)
print('num3', num3)
프로그램 2.11) 리스트로 2차원 배열 생성
다음은 리스트로 3행 3열의 2차원 배열을 생성하는 예이다.
반복문과 인덱스를 사용하여 리스트 원소를 참조하는 여러가지 예를 볼 수 있다.
# 2차원 배열
scores = [[75, 90, 85], [60, 100, 75], [90, 70, 80]]
print("scores", scores)
for score in scores:
for num in score:
print(num, end = ' ')
print()
print()
print("scores[0][1]", scores[0][1])
print("scores[2]", scores[2])
print("scores[2][2]", scores[2][2])
프로그램 2.12) 볼링 게임 점수 계산
볼링 게임에서 점수를 계산하는 프로그램을 리스트를 사용하여 작성해 보자.
볼링 게임은 총 10 프레임으로 구성되고 각 프레임에서 최대 2번까지 공을 굴릴 수 있다.
첫 번째 굴린 공이 10개 핀을 모두 쓰러뜨리면 '스트라이크'라고 부르고, 공을 2번 굴려서 10개 핀을 모두 쓰러뜨리면 '스페어'라고 한다.
한 게임에서 획득 가능한 최대 점수는 300점이다.
<점수 계산 규칙>
- 스트라이크를 치면, 이후 2회 쓰러뜨린 핀의 수를 더해서 점수를 계산한다.
- 스페어를 치면, 이후 1회 쓰러뜨린 핀의 수를 더해서 점수를 계산한다.
- 스트라이크나 스페어를 치지 못한 경우, 쓰러뜨린 핀의 수를 더해서 점수를 계산한다.
- 10 프레임에서 스트라이크 또는 스페어를 치면, 각각 2회와 1회의 보너스 드로우가 주어진다.
- 10프레임에서 보너스 드로우를 포함하여 최대 3번의 스트라이크를 친 경우 30점을 얻을 수 있다.
- 스트라이크와 스페어를 친 프레임에서는 다음 프레임의 점수가 나올 때까지 점수 계산을 보류한다.
# 볼링 게임 점수 계산 프로그램
score1 = [(8,0), (4,3), (8,2), (4,6), (2,6), (10,0), (9,0), (10,0), (8,2), (10,0), (10,10)]
score2 = [(10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,10)]
score_list = [score1, score2]
for score in score_list:
i = total = 0
frame = []
for first, second in score:
f_total = first + second
next_first, next_second = score[i+1]
if first == 10:
result = 'STRIKE'
f_total += next_first + next_second
if i != 9 and next_first == 10:
next_next_first, next_next_second = score[i+2]
f_total += next_next_first
elif (first + second) == 10:
result = 'SPARE'
f_total += next_first
else :
result = 'NONE'
total += f_total
frame.append((f_total, result))
i += 1
if i == 10 :
break
print(frame)
print("Total = ", total)
print()코드를 살펴보았다.
score1 = [(8,0), (4,3), (8,2), (4,6), (2,6), (10,0), (9,0), (10,0), (8,2), (10,0), (10,10)]
score2 = [(10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,10)]
score_list = [score1, score2]두 볼링 경기 결과 score1과 score2를 입력한다.
score_list에 score1과 score2를 입력한다.
score_list에는 [[(8,0), (4,3), (8,2), (4,6), (2,6), (10,0), (9,0), (10,0), (8,2), (10,0), (10,10)], [(10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,0), (10,10)]]의 형태로 데이터가 저장되어 있을 것이다.
for score in score_list:
i = total = 0
frame = []
for first, second in score:
f_total = first + second
next_first, next_second = score[i+1]score_list에 있는 score을 반복한다. score1 → score2 순서로 계산한다는 뜻이다.
총 점수를 받아야 하는 total과 리스트 순서를 표시할 i를 초기화한다.
frame 리스트에는 각 프레임의 점수와 결과를 입력할 것이고, 초기화한다.
f_total(각 프레임의 총 점수)에는 first+second 점수를 입력한다.
그리고 다음 score 튜플에서 next_first와 next_second를 입력받는다.
if first == 10:
result = 'STRIKE'
f_total += next_first + next_second
if i != 9 and next_first == 10:
next_next_first, next_next_second = score[i+2]
f_total += next_next_first
elif (first + second) == 10:
result = 'SPARE'
f_total += next_first
else :
result = 'NONE'first가 10, 즉 스트라이크라면 결과를 스트라이크로 저장하고 f_total에 next_first와 next_second값을 더한다.
만약 1~9프레임인데 다음 결과도 스트라이크라면(스트라이크-스트라이크 연속) 다다음 score 튜플에서 next_next_first, next_next_second를 입력받아 next_next_first를 f_total에 더한다.
만약 first와 second를 더해서 10점, 즉 스페어라면 결과를 스페어로 저장하고 next_first 점수만 추가로 f_total에 저장한다.
두 경우 다 아니라면 추가적으로 처리해줄 것이 없고, 결과를 none으로 저장한다.
total += f_total
frame.append((f_total, result))
i += 1
if i == 10 :
break각 프레임의 총 점수를 볼링 경기의 총 점수에 더한 뒤에 frame 리스트에 각 프레임의 총 점수와 결과를 추가한다.
다음 프레임으로 가기 위해 1을 추가한다.
i는 0에서부터 시작했기 때문에 i가 10인 경우는 11프레임이다. 따라서 끝낸다.
print(frame)
print("Total = ", total)
print()각 결과를 출력한다.
2.5 집합과 딕셔너리
집합(set) 자료형은 수학의 집합과 유사한 자료구조로 집합 연산자를 지원한다.
리스트와 다른 점은 원소의 나열 순서가 없으며 원소의 중복을 허용하지 않는다는 것이다.
집합은 다음과 같이 set() 함수 또는 {} 기호를 사용하여 생성한다.
s1 = set([1, 2, 3, 3, 2])
s2 = {2, 3, 4}집합은 원소의 중복을 허용하지 않기 때문에 s1은 {1, 2, 3}으로 선언한 것과 동일하다
또한 리스트처럼 원소의 나열 순서를 고려하지 않기 때문에 인덱스로 원소를 참조하는 것은 불가능하다.
집합 자료형은 원소의 멤버십(in, not in)을 판단하거나 집합 연산으로 합집합(|), 교집합(&), 차집합(-)을 구하는데 유용하다.
또한 집합의 중복 원소를 제거하는 경우에도 유용하다.
집합에 원소를 추가할 때는 add() 함수를 사용하고, 제거할 때는 remove() 함수를 이용한다.
update() 함수를 사용하면 집합에 여러 개의 원소를 한번에 추가할 수 있다.
프로그램 2.13) 집합 자료형
여러가지 집합 연산을 실행한 예시이다.
# 집합 자료형 사용하기
s1 = set([1, 2, 3, 3, 2, 'a'])
s2 = {2, 3, 4, 'a'}
print("s1 =", s1)
print("s2 =", s2)
print("2 in s1 =", 2 in s1)
print("5 in s2 =", 5 in s2)
print("s1 | s2 =", s1 | s2)
print("s1 & s2 =", s1 & s2)
print("s1 - s2 =", s1 - s2)
print("s2 - s1 =", s2 - s1)
s2.add(9)
s1. update({4, 5, 6})
s1. remove(3)
print("s1 =", s1)
print("s2 =", s2)
딕셔너리(dictionary)는 각 항목이 키(key)와 값(value)의 쌍으로 구성된 자료형이다.
리스트의 원소를 정수 인덱스로 조회하는데 비해, 딕셔너리의 항목은 키워드(키)를 통해서 접근할 수 있어서 코드의 가독성을 높일 수 있다.
파이썬의 딕셔너리를 활용하여 연락처 관리, 외국어 사전, 성적 관리 프로그램 등을 만들 수 있다.
아래 표는 딕셔너리의 기본 함수들이다.
|
함수
|
기능
|
|
items()
|
딕셔너리의 각 항목을 튜플(key, value) 리스트로 반환한다.
|
|
keys()
|
딕셔너리의 각 항목의 키(key) 만을 추출하여 리스트로 반환한다.
|
|
values()
|
딕셔너리의 각 항목의 값(value) 만을 추출하여 리스트로 반환한다.
|
프로그램 2.14) 단어 출현 빈도
파이썬의 딕셔너리를 사용하여 문장에 나오는 단어의 출현 빈도를 계산하려고 한다.
실행 결과와 같이 출력되도록 프로그램을 작성하시오.
풀이) 문자열을 lower() 함수를 사용하여 소문자로 변환한 후, split() 함수를 시행하여 단어 단위로 분리한다.
그 다음 각 단어를 딕셔너리의 키로 설정하여 단어의 출현 빈도를 기억한다.
sentence = "Van Rossum was born and raised in the Netherlands, \
where he received a master's degree in mathematics and computer \
science from the University of Amsterdam in 1982.\
In December 1989, Van Rossum had been looking for a hobby \
programming project that would keep him occupied during the week \
around Christmas as his office was closed when he decided to write \
an interpreter for a new scripting language he had been \
thinking about lately, a descendant of ABC that would appeal to Unix / C hackers "
sentence = sentence.lower()
words = sentence.split()
dic = {}
for word in words :
if word not in dic :
dic[word] = 0
dic[word] += 1
print("# of different words =", len(dic))
n = 0
for word, count in dic.items() :
print(word, '(%d)' % count, end = ' ')
n += 1
if n % 3 == 0 :
print()코드를 살펴보았다.
sentence = sentence.lower()
words = sentence.split()
dic = {}lowers를 통해서 문장의 대문자를 소문자로 바꾸고 단어대로 나눈다.
단어가 나온 횟수를 저장할 딕셔너리 dic을 만들었다.
for word in words :
if word not in dic :
dic[word] = 0
dic[word] += 1아까 split을 통해 저장한 words 리스트에 있는 word를 하나씩 dic과 대조하는 과정이다.
if문을 통해 이전에 값이 없었다면 추가한다.
만약 딕셔너리에 있다면 dic[word]의 count를 1 증가시킨다.
print("# of different words =", len(dic))
n = 0
for word, count in dic.items() :
print(word, '(%d)' % count, end = ' ')
n += 1
if n % 3 == 0 :
print()총 나온 문자의 갯수, 문자, count를 출력한다.
n을 통해 문자를 3개씩 출력한다.

댓글 열어뒀습니다.
질문이나 수정 사항 있다면 알려주세요

