

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- htmlinjection
- EC2
- 와이어샤크
- fork-bomb
- python
- 자료구조
- CodeEngn
- docker
- cloud
- Systemhacking
- Reversing
- backjoon
- Dreamhack
- datastructure
- bWAPP
- beebox
- wireshark
- c
- Reflected
- 유석종교수님
- Linux
- mount
- acc
- AWS
- basicrce3
- pwnable
- SISS
- cgroup
- System
- 백준
- Today
- Total
Ctrl + Shift + ESC
[Dreamhack] Reverse Engineering Stage 2 - Background: Binary 본문
[Dreamhack] Reverse Engineering Stage 2 - Background: Binary
단축키실행해보세요 2022. 4. 30. 23:49서론
어떤 대상에게 명령을 내리려면, 그 대상과의 소통에 사용할 언어가 필요하다.
컴퓨터 과학자들은 컴퓨터에 명령을 내리기 위해 기계어(Machine Language)라는 컴퓨터의 언어를 정의했다.
그리고 필요한 연산을 컴퓨터가 대신하도록 기계어로 명령을 내렸다.
기계어는 0과 1로 이루어져 있어서 사람이 이해하기 어려웠고, 이를 이용해서 컴퓨터에 명령을 내리는 것은 비효율적이었다.
컴퓨터 과학자들은 사람이 이해하기 쉬운 새로운 언어로 어셈블리어(Assembly Language)를 고안했고, 이를 기계어로 번역해주는 어셈블러(Assembler)를 개발했다.
어셈블리어는 기계어에 비하면 효율적이었으나, 규모가 큰 프로그램을 개발하기에는 부족했다.
그래서 C, C++, Go, Rust 등을 비롯하여 어셈블리어보다 더욱 사람이 이해하기 쉬운 언어들을 만들었고, 이들을 기계어로 번역해주는 컴파일러(Compiler)를 개발했다.
이 언어들은 프로그램 개발의 효율을 극대화해주었고 현재까지도 널리 사용되고 있다.
프로그래밍에 사용하는 언어 중, 사람이 이해하기 쉬운 언어를 고급 언어(High-Level Language)라고 부르며, 그 반대의 언어를 저급 언어(Low-Level Language)라고 부른다.
위에서 살펴본 C, C++, Go, Rust가 전자에, 기계어나 어셈블리어가 후자에 속한다.
초기에는 컴파일 이론 및 관련된 기술들이 미흡해서 고급 언어로 개발하는 것이 만족스럽지 않을 때가 있었으나 최근에는 단점이 거의 보완되었다.
생산성의 측면에서 고급 언어가 저급 언어보다 효율적이기 때문에 이제는 특별한 경우를 제외하고는 저급 언어로 프로그램을 개발하지 않는다.
프로그램
프로그램(Program) : 연산 장치가 수행해야 하는 동작을 정의한 일종의 문서
프로그램을 연산 장치에 전달하면, CPU는 적혀있는 명령들을 처리하여 프로그래머가 의도한 동작을 수행한다.
사용자가 정의한 프로그램을 해석하여 명령어를 처리할 수 있는 연산 장치를 programmable하다고 하는데, 현대의 컴퓨터가 대표적인 programmable 연산 장치이고, 일반 계산기는 대표적인 non-programmable 연산 장치이다.
과거에는 프로그램을 내부 저장 장치에 저장할 수 없어서 사람이 전선을 연결하여 컴퓨터에 전달하거나, 천공 카드(Punched card)에 프로그램을 기록하여 재사용하는 방식을 사용했다.
전자의 방식을 사용한 컴퓨터가 에니악(ENIAC)인데, 프로그램이 바뀔 때마다 배선을 재배치해야 했으므로 매우 비효율적이었고, 크기가 큰 프로그램을 사용하기도 어려웠다.
이런 단점을 해결한 Stored-Program Computer가 1950년경에 최초로 상용화되었다.
이 컴퓨터는 프로그램을 메모리에 전자적으로, 또는 광학적으로 저장할 수 있었는데 기존의 컴퓨터들보다 월등히 많은 프로그램을 저장할 수 있었으며, 저장된 프로그램을 사용하는 것도 간편했다.
이제는 컴퓨터의 대부분이 Stored-Program Computer의 형태로 개발된다.
소프트웨어 개발자, 해커 등 많은 정보 분야의 엔지니어들이 프로그램을 바이너리(Binary)라고 부르곤 하는데, 이는 Stored-Program Computer에서 프로그램이 저장 장치에 이진(Binary) 형태로 저장되기 때문이다.
텍스트가 아닌 다른 데이터들도 바이너리라고 불리긴 하지만, 많은 경우에 바이너리라고 하면 프로그램을 의미한다.
컴파일러와 인터프리터
프로그래밍 언어(Programming Language) : 프로그램을 개발하기 위해 사용하는 언어
서론에서 언급한 C, C++, Go, Rust와 같은 고급 언어들과 어셈블리어, 기계어 등의 저급 언어들이 있다.
소스 코드(Source Code) : CPU가 수행해야 할 명령들을 프로그래밍 언어로 작성한 것
컴파일(Compile) : 소스 코드를 컴퓨터가 이해할 수 있는 기계어의 형식으로 번역하는 것
컴파일을 해주는 소프트웨어는 컴파일러(Compiler)라고 불리는데, 대표적으로 GCC, Clang, MSVC 등이 있다.
한번 컴파일되면 결과물이 프로그램으로 남기 때문에 언제든지 이를 실행하여 같은 명령을 처리하게 할 수 있다.
모든 언어가 컴파일을 필요로 하는 것은 아니고, Python, Javascript 등의 언어는 컴파일을 필요로 하지 않는다.
이 언어들은 사용자의 입력, 또는 사용자가 작성한 스크립트를 그때 그때 번역하여 CPU에 전달한다.
이 동작이 통역과 비슷하기 때문에 인터프리팅(Interpreting)이라고 불리며, 이를 처리해주는 프로그램을 인터프리터(Interpreter)라고 한다.
컴파일은 아무 배경지식이 없는 사람이 책을 읽을 수 있도록 배경지식을 엮고, 번역하여 하나의 번역본을 만드는 과정으로, 인터프리팅은 동시 통역사를 거쳐 대화하는 것으로 비유하여 이해할 수 있다.
전자는 결과물이 남아서 언제든 다시 읽어볼 수 있지만 한 번 번역하는데 시간이 많이 필요하고, 후자는 상대방과 빠르게 의사소통할 수 있지만, 같은 이야기를 하더라도 매번 통역사를 거쳐야 한다는 단점이 있다.
컴파일 과정
C언어로 작성된 코드는 일반적으로 전처리(Preprocess), 컴파일(Compile), 어셈블(Assemble), 링크(Link)의 과정을 거쳐 바이너리로 번역된다.
// Name: add.c
#include "add.h"
#define HI 3
int add(int a, int b) { return a + b + HI; } // return a+b// Name: add.h
int add(int a, int b);컴파일(Compile)의 정확한 의미는 어떤 언어로 작성된 소스 코드(Source Code)를 다른 언어의 목적 코드(Object Code)로 번역하는 것이다.
이런 맥락에서, 소스 코드를 어셈블리어로, 또는 소스 코드를 기계어로 번역하는 것 모두 컴파일이라고 볼 수 있다.
전처리
전처리(Preprocessing) : 컴파일러가 소스 코드를 어셈블리어로 컴파일하기 전에, 필요한 형식으로 가공하는 과정
언어마다 조금씩 다르지만, 컴파일 언어의 대부분은 다음의 전처리 과정을 거친다.
1. 주석 제거
주석은 개발자가 코드 이해를 돕기위해 작성하는 메모이다. 주석은 프로그램의 동작과 상관이 없으므로 전처리 단계에서 모두 제거된다.
2. 매크로 치환
#define으로 정의한 매크로는 자주 쓰이는 코드나 상숫값을 단어로 정의한 것이다. 전처리 과정에서 매크로의 이름은 값으로 치환된다.
3. 파일 병합
일반적인 프로그램은 여러 개의 소스와 헤더 파일로 이루어져 있다.
컴파일러는 이를 따로 컴파일해 합치기도 하지만, 어떠한 경우는 전처리 단계에서 파일을 합치고 컴파일하기도 한다.
# 1 "add.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 31 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "<command-line>" 2
# 1 "add.c"
# 1 "add.h" 1
int add(int a, int b);
# 2 "add.c" 2
int add(int a, int b) { return a + b + 3; }위의 add.i는 add.c를 전처리한 결과이다.
gcc에서는 -E 옵션을 사용하여 소스 코드의 전처리 결과를 확인할 수 있다.

결과를 살펴보면 먼저 소스 코드의 주석이었던 // return a+b가 사라졌고, HI가 3으로 치환되었다.
그리고 add.h의 내용이 #include에 의해 병합되었다.
컴파일
컴파일(Compile) : C로 작성된 소스 코드를 어셈블리어로 번역하는 것
이 과정에서 컴파일러는 소스 코드의 문법을 검사하는데, 코드에 문법적 오류가 있다면 컴파일을 멈추고 에러를 출력한다.
또한, 컴파일러는 코드를 번역할 때, 몇몇 조건을 만족하면 최적화 기술을 적용하여 효율적인 어셈블리 코드를 생성한다.
gcc에서는 -O -O0 -O1 -O2 -O3 -Os -Ofast -Og 등의 옵션을 사용하여 최적화를 적용할 수 있다.
// Name: opt.c
// Compile: gcc -o opt opt.c -O2
#include <stdio.h>
int main() {
int x = 0;
for (int i = 0; i < 100; i++) x += i; // x에 0부터 99까지의 값 더하기
printf("%d", x);
}예를 들어, 위의 opt.c를 최적화하여 컴파일하면, 컴파일러는 반복문을 어셈블리어로 옮기는 것이 아니라, 반복문의 결과로 x가 가질 값을 직접 계산하여, 이를 대입하는 코드를 생성한다.
이를 통해 사용자가 작성한 소스 코드와 연산 결과는 같으면서도, 최적화를 적용하지 않았을 때보다 더 짧고, 실행 시간도 단축되는 어셈블리 코드가 만들어지게 된다.
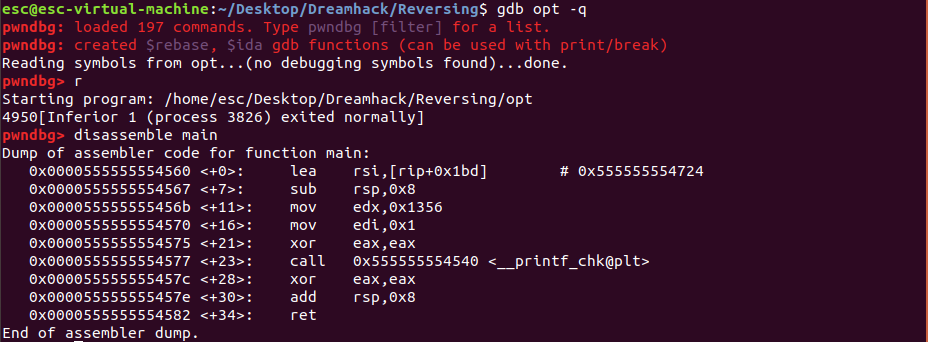
“-S” 옵션을 이용하면 소스 코드를 어셈블리 코드로 컴파일할 수 있다.

어셈블
어셈블(Assemble) :은 컴파일로 생성된 어셈블리어 코드를 ELF형식의 목적 파일(Object file)로 변환하는 과정
여기서 ELF는 리눅스의 실행파일 형식이다.
윈도우에서 어셈블한다면 목적 파일은 PE형식을 갖는다.
목적 파일로 변환되고 나면 어셈블리 코드가 기계어로 번역되므로 더이상 사람이 해석하기 어려워진다.


gcc의 “-c” 옵션을 통해 add.S를 목적 파일로 변환하고, 결과로 나온 파일을 16진수로 출력한 것이다.
읽을 수 있는 문자열 중 코드로 보이는 것은 없다.
링크
링크(Link) : 여러 목적 파일들을 연결하여 실행 가능한 바이너리로 만드는 과정
링크가 필요한 이유를 다음의 코드를 통해 이해했다.
위 코드에서 printf함수를 호출하지만, printf 함수의 정의는 hello-world.c 에 없으며, libc라는 공유 라이브러리에 존재한다.
libc는 gcc의 기본 라이브러리 경로에 있는데, 링커는 바이너리가 printf를 호출하면 libc의 함수가 실행될 수 있도록 연결해준다.
링크를 거치고 나면 실행할 수 있는 프로그램이 완성된다.

위는 add.o를 링크하는 명령어이다.
링크 과정에서 링커는 main함수를 찾는데, add의 소스 코드에는 main함수의 정의가 없으므로 에러가 발생할 수 있다.
이를 방지하기 위해 --unresolved-symbols를 컴파일 옵션에 추가했다.
디스어셈블
바이너리를 분석하려면 바이너리를 읽을 수 있어야 한다.
그런데 컴파일된 프로그램의 코드는 기계어로 작성되어 있으므로 이를 그 자체로 이해하기는 매우 어렵다.
그래서 분석가들은 이를 어셈블리어로 재번역하고자 했다.
이 과정은 앞서 살펴본 어셈블의 역과정이므로 디스어셈블(Disassemble)이라고 부른다.
다음 명령어로 쉽게 디스어셈블된 결과를 확인할 수 있다.
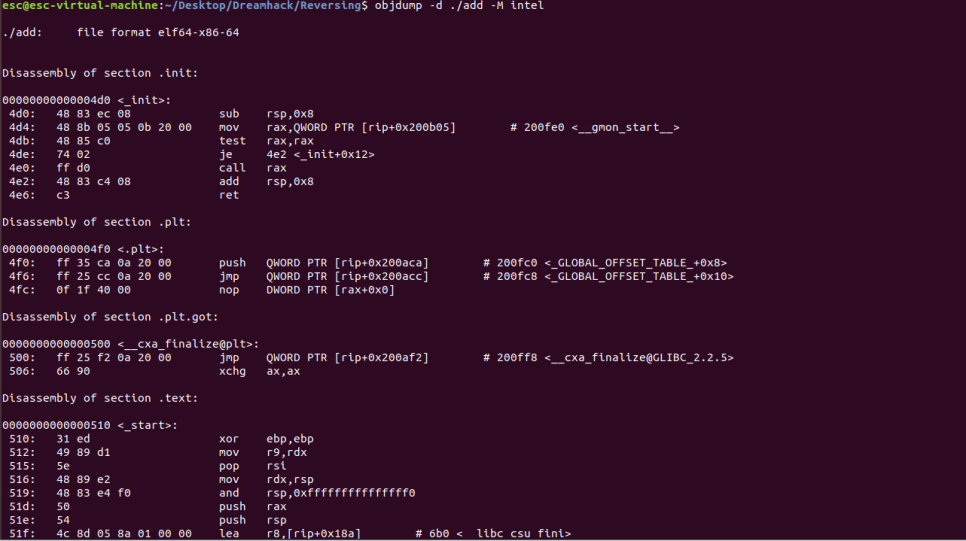
길어서 이하 생략
디컴파일
디스어셈블 기술의 등장으로 바이너리를 분석하기 보다 쉬워졌지만, 규모가 큰 바이너리의 동작을 어셈블리 코드만으로 이해하기는 어려웠다.
그래서 리버스 엔지니어들은 어셈블리어보다 고급 언어로 바이너리를 번역하는 디컴파일러(Decompiler)를 개발했다.
어셈블리어와 기계어는 거의 일대일로 대응되어 오차없는 디스어셈블러를 개발할 수 있었으나 고급 언어와 어셈블리어 사이에는 이런 대응 관계가 없다. 또한, 코드를 작성할 때 사용했던 변수나 함수의 이름 등은 컴파일 과정에서 전부 사라지고, 코드의 일부분은 최적화와 같은 이유로 컴파일러에 의해 완전히 변형되기도 한다.
이런 어려움으로 인해 디컴파일러는 일반적으로 바이너리의 소스 코드와 동일한 코드를 생성하지는 못한다.
그러나, 이 오차가 바이너리의 동작을 왜곡하지는 않으며, 디스어셈블러를 사용하는 것 보다 압도적으로 분석 효율을 높여주기 때문에, 디컴파일러를 사용할 수 있다면 반드시 디컴파일러를 사용하는 것이 유리하다.
특히 최근에는 Hex Rays, Ghidra를 비롯한 뛰어난 디컴파일러들이 개발되어서 분석의 효율을 더욱 높여주고 있다.
코스 요약
- 프로그램: 컴퓨터가 실행해야 할 명령어의 집합, 바이너리라고도 불림
- 전처리: 소스 코드가 컴파일에 필요한 형식으로 가공되는 과정
- 컴파일: 소스 코드를 어셈블리어로 번역하는 과정
- 어셈블: 어셈블리 코드를 기계어로 번역하고, 실행 가능한 형식의 변형하는 과정
- 링크: 여러 개의 목적 파일을 하나로 묶고, 필요한 라이브러리와 연결해주는 과정
- 디스어셈블: 바이너리를 어셈블리어로 번역하는 과정
- 디컴파일: 바이너리를 고급 언어로 번역하는 과정


